
So, WTF is Deep Learning Anyway?


(Re-edited version of the original published in The DoT Blog)
While deep learning isn't new—it was introduced by Dr. Rina Dechter in 1986—it's only in recent years that this approach has gained fame and popularity among users and particularly among software companies incorporating it into their analytics arsenals.
So, following on my previous WTF post on Machine Learning, it just makes sense to continue in this line of thought to address another popular and trendy concept.
Then, without further ado, let's explain WTF deep learning is, shall we?
Simply put, and as inferred from my previous post(So WTF is Machine Learning Anyway?), deep learning is one of many approaches to machine learning we can find out there, alongside other approaches like decision tree learning, association rule learning, or Bayesian networks but, while traditional machine learning often relies on human-engineered features, deep learning's key distinction is its ability to automatically discover and extract features from raw data through multiple processing layers.
Deep learning enables us to train computers to perform tasks including speech recognition, image identification, or making predictions by, instead of organizing data to run through predefined equations, setting up basic parameters about the data and training the computer so it can "learn" by recognizing patterns through many layers of processing.
For example, in image recognition, early layers might learn to detect edges, middle layers might recognize shapes like circles or rectangles, and deeper layers might identify complex objects like faces or cars, all without being explicitly programmed to look for these specific features.
We will touch more on these layers in the following sections.
So, What Has Made Deep Learning so Popular?
Many factors have played out to enable the popularity of machine learning in general as well as deep learning in particular.
Today, modern deep learning provides a powerful framework for supervised learning (where the algorithm learns from labeled training data to make predictions) and for addressing increasingly complex problems. Consequently, it has gained huge popularity in many computing fields, including computer vision, speech and audio recognition, natural language processing (NLP), bioinformatics, drug design and many others, but why? This popularity stems from multiple factors.
On one hand, there's the rapid evolution of deep learning algorithms themselves. But equally important has been the convergent evolution of core computing technologies including big data, cloud computing, and in-memory processing. These advancements have enabled deep learning algorithms—which require intensive computational resources—to be deployed on increasingly faster and more efficient computing infrastructures.
On the other hand, the evolution and consumerization of peripheral technologies like mobile and smart devices have made it possible for providers to embed deep learning functionality into more systems for expanding use cases and to reach broader audiences that can use and develop deep learning in a more "natural" way.
How Does Deep Learning Work?
In general, most deep learning architectures are constructed from a type of computing system called artificial neural networks (ANN)—I know, we'll get to its own WTF explanation soon—yet they can also include other computing structures and techniques.
Inspired by the structure and functions of the brain, deep learning's usage of ANNs recreates the interconnection of neurons by developing algorithms that mimic the biological structure of the brain.
Let's break down how neural networks actually process information (Figure 1):
Each artificial unit (neuron) receives input signals, and multiplies them by weights (parameters that determine importance)
These weighted inputs are summed together and passed through an activation function (like ReLU or sigmoid)1 that determines whether and how strongly the neuron "fires"
The output signals from one layer become input signals for the next layer
During training, the network compares its outputs with the correct answers and adjusts weights through a process called backpropagation to minimize errors.
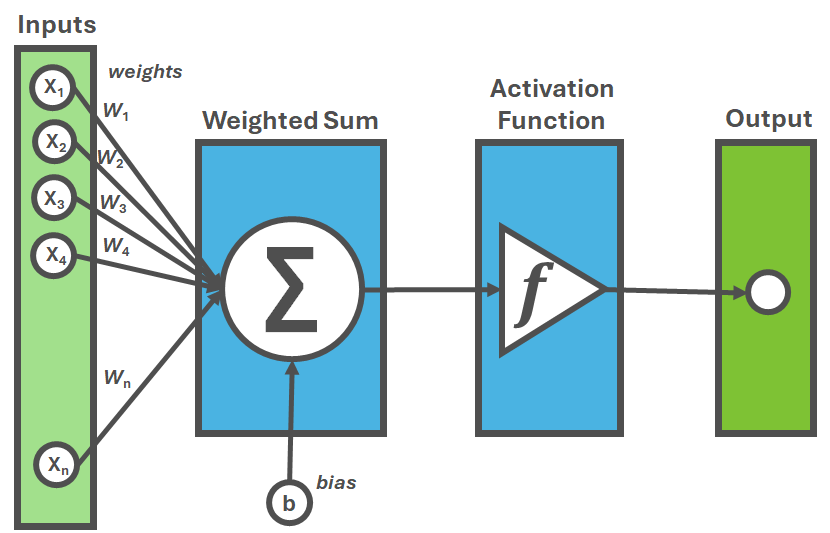
Within an ANN, units are organized in discrete layers and connected to other units so that each layer focuses on a specific feature to learn (shapes, patterns, etc.).
Each layer then creates a depth of "learning" or "feature to learn" so that, by adding more layers and more units within a layer, a deep network can represent functions of increasing complexity or depth.
It's this layering or depth that gives deep learning its name (Figure 2).
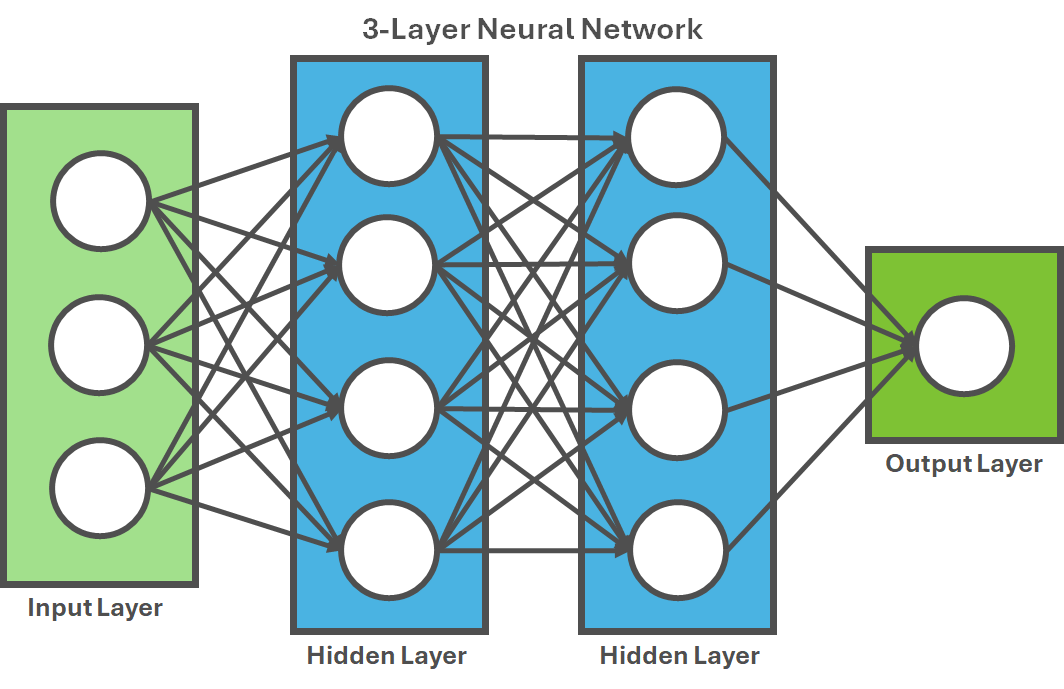
Until now, most, if not all deep learning applications deal with tasks or problems that, as the previous figure shows, consist of mapping an input vector (a collection of numerical values representing features of the input, like pixel values in an image) to an output vector (the desired prediction, like probabilities of different object categories), allowing the solving of problems that require sufficiently large models and datasets.
So, consider for example, a neural network that recognizes handwritten digits with the following structure (Figure 3):
Input vector: 784 numbers representing pixel intensities in a 28×28 image
Hidden layers: Process these inputs through weighted connections
Output vector: 10 numbers representing probabilities that the image is each digit (0-9)
The network learns appropriate weights through repeated exposure to thousands of labeled examples.
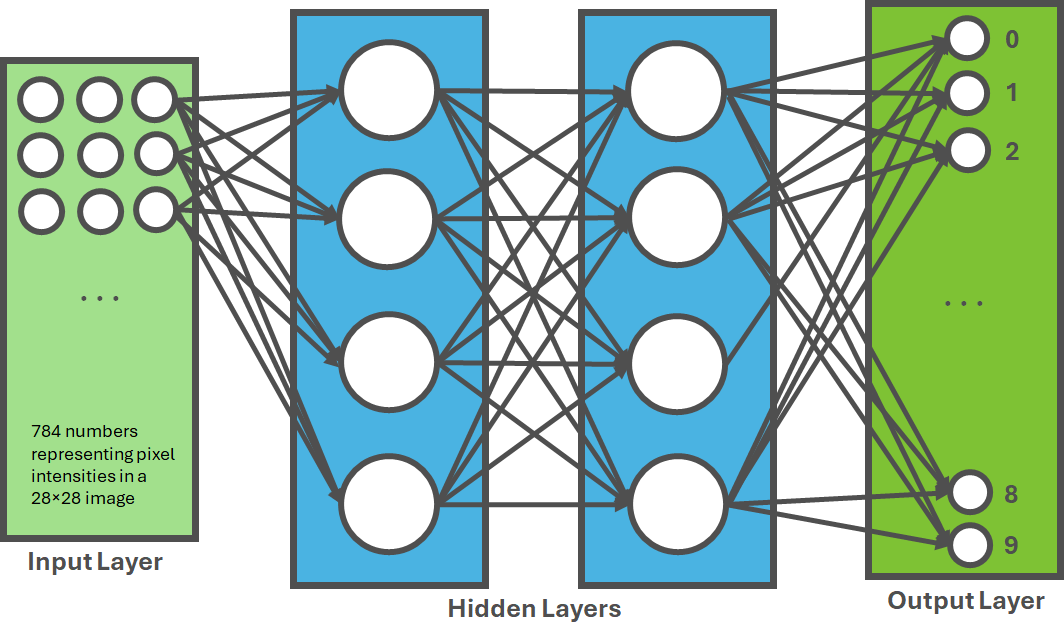
These problems are commonly those that humans would solve relatively easily without much reflection (identifying forms and shapes, for example), and yet due to the increasing computing power available and the continuous evolution of deep learning, computers can now perform these tasks even faster than humans.
It's clear then that both machine learning in general and deep learning in particular change the common paradigm for analytics. Instead of developing algorithms to specifically instruct a computer system on how to solve a problem, a model is developed and trained so that the system can "learn" and solve the problem by itself (Figure 4).
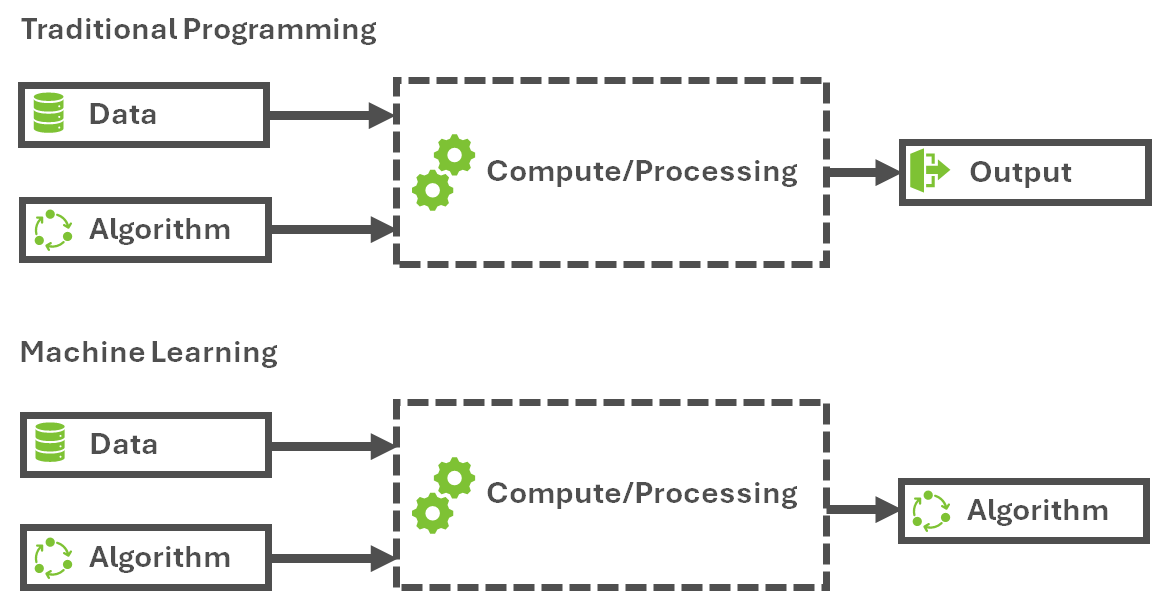
A key advantage of deep learning is that while a traditional approach starts by using available data to perform feature engineering (manually identifying which characteristics of the data are most important for prediction) and then selecting a model to estimate parameters within an often repetitive and complex cycle to finally arrive at an effective model, deep learning replaces this with a layered approach in which each layer can recognize key features from patterns or regularities in the data.
Hence, deep learning replaces model formulation by using characterizations (or layers) organized hierarchically that can learn to recognize features from the available data (Figure 5), which results in the construction of "systems of prediction" that can:
Avoid using hard parameters and business rules
Make better generalizations
Improve continuously
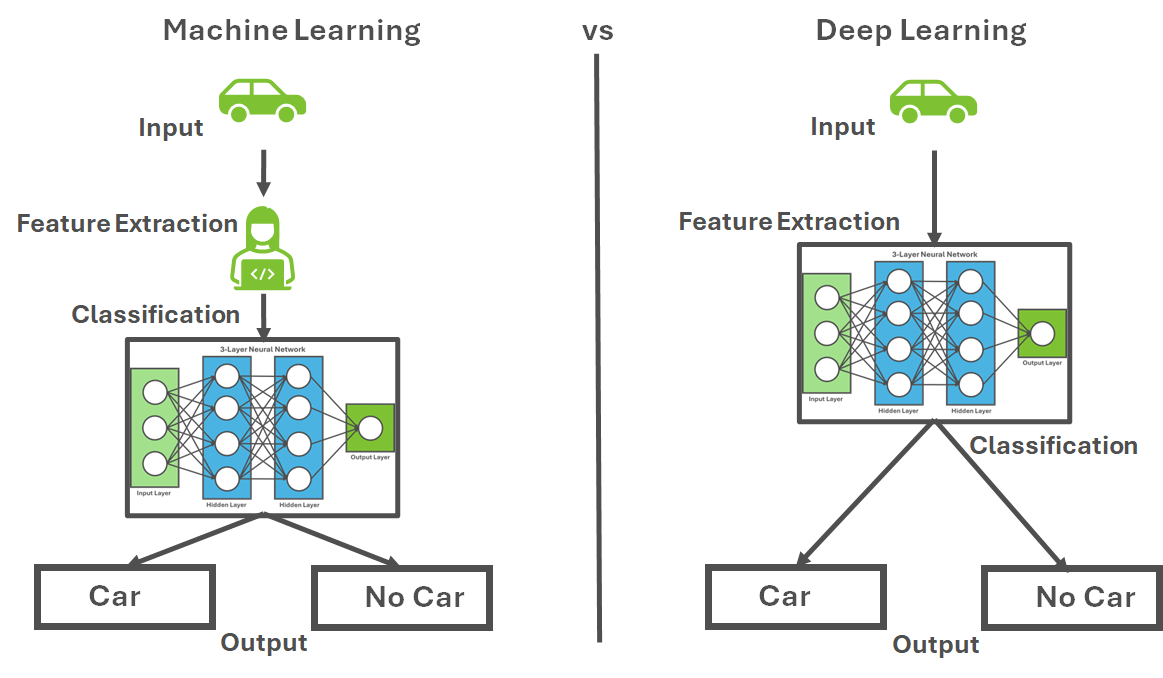
To further illustrate the difference between traditional machine learning and deep learning approaches let’s explore a face recognition case:
Traditional ML approach for face recognition:
Engineer features manually: Identify facial landmarks, measure distances between eyes, calculate face symmetry
Feed these hand-crafted features to classifiers like SVMs or Random Forests
Make predictions based on these pre-defined features
Deep learning approach:
Feed raw pixel data directly to the neural network
Early layers automatically learn to detect edges and simple patterns
Middle layers combine these into more complex features like eyes, noses, mouths
Deep layers learn to recognize complete faces and their variations
The entire feature extraction process is learned, not programmed
On the downside, one common challenge when deploying deep learning applications is that they require intensive computational power due to:
The iterative nature of deep learning algorithms
The increasing complexity as the number of layers increases
The need for large volumes of data to train the neural networks
So, for perspective on computational demands:
Training a state-of-the-art image recognition model might require processing millions of images multiple times through networks with hundreds of layers and billions of parameters, taking days or weeks on specialized hardware like GPUs or TPUs, and consuming enough electricity to power several households during that period.
Still, deep learning's continuous improvement feature sets an ideal stage for any organization to implement dynamic behavior features within their analytics platforms.
Applications of Deep Learning
Today, deep learning has already been applied in many industries and lines of business, and its use continues to increase at a steady pace. Some areas where deep learning has been successfully applied include:
Recommendation Systems
This is perhaps the flagship use case for machine learning and deep learning. Companies including Amazon and Netflix have worked on using these systems to develop platforms that can, with good chances of accuracy, predict what a viewer might be interested in watching or purchasing next, based on past behavior.
Deep learning enhances these recommendations in complex environments by increasingly learning users' interests across multiple platforms.
For instance, Netflix's recommendation engine processes not just what you've watched, but how long you watched it, when you watched it, what device you used, and patterns across millions of other users to suggest content you're likely to enjoy, all through neural networks that can capture subtle patterns traditional algorithms might miss.
Image and Speech Recognition
Another common application of deep learning in the software industry is speech and image recognition.
On the speech recognition front, companies like Alphabet (Google), Apple, and Microsoft have applied deep learning to products like Google Assistant, Siri, and Alexa to recognize voice patterns and human speech.
On the image recognition side, despite its challenges, projects already applying deep learning with different levels of success can be found. Companies like Amazon with Rekognition are using deep learning to recognize and acquire real-time insights from the behavior of cars, people, and practically any object.
Applications like these have enormous potential in sectors including law enforcement or self-driving cars.
Consider for example, autonomous vehicles, which use convolutional neural networks (CNNs) —a specialized type of deep learning architecture—to process camera feeds and identify pedestrians, traffic signs, lane markings, and other vehicles in real-time, making driving decisions in milliseconds based on these inputs.
Natural Language Processing
Neural networks and deep learning have been key for the development of natural language processing (NLP), an area of artificial intelligence that develops techniques and solutions that allow "natural" interaction between computers and human languages, especially to enable the processing of large amounts of natural language data.
Companies like MindMeld use deep learning and other techniques to develop intelligent conversational interfaces.
Modern language models like GPT, BERT, and others use transformer architectures—specialized deep learning models with attention mechanisms—to understand context in text.
For example, these models can distinguish between "bank" meaning a financial institution versus a riverside in different contexts, something traditional rule-based systems struggled with tremendously.
We could continue describing more use cases for deep learning, but perhaps it's fair to say the number and types of applications keep growing rapidly.
Ok, So… What is Out There in the Market?
Currently, there are varied options for using or deploying deep learning, both to start experimenting and developing or to deploy enterprise-ready solutions that apply deep learning.
For organizations with the will for development and innovation, open source-based deep learning frameworks and analytics like TensorFlow, Caffe, or PyTorch represent great opportunities to get up and running. These frameworks offer different advantages: TensorFlow provides an extensive ecosystem and production deployment tools, PyTorch offers dynamic computation graphs that many researchers prefer for experimentation, while specialized frameworks like Hugging Face Transformers simplify working with state-of-the-art language models.
Of course, other excellent solutions for developing and applying deep learning include data science platforms like Dataiku, DataRobot, or former DataScience.com, which was recently acquired by Oracle.
Users and organizations can also take a practical approach and use niche vertical solutions like CrowdStrike's cloud-native endpoint protection platform, Flatiron Health's healthcare software, or Elastic’s security intelligence & analytics (SIA) solutions, among many others.
And?
Deep learning and machine learning solutions are increasingly accessible to companies of all sizes, driving continuous and rapid evolution of these technologies within the market landscape. Unsurprisingly, user expectations remain high as they seek to address and solve increasingly complex problems.
Today, deep learning serves as a core component of many AI applications in the software industry, even though it often operates as a transparent and invisible technology.
This widespread adoption suggests that with new advances and techniques emerging so frequently, we may be witnessing just the beginning of a new era in the AI and deep learning marketplace.
It appears that deep learning has established deep roots within the industry—or has it?
ReLU (Rectified Linear Unit):
ReLU, short for Rectified Linear Unit, is one of the go-to activation functions in neural networks and deep learning. It keeps things simple, if the input’s positive, it passes it through unchanged; if not, it just returns zero. Mathematically, it's defined as:
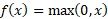
ReLU helps models train faster and handle large, complex datasets by introducing non-linearity without saturating gradients, which often improves performance compared to older functions like sigmoid.
Sigmoid:
The sigmoid function is a classic activation function that squeezes any real number into a range between 0 and 1, creating that familiar S-shaped curve. It’s often used when you want to model probabilities or make binary decisions in neural networks. It's defined as:
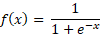
and is mainly used when outputs need to be interpreted as probabilities. However, in deep networks, it can suffer from vanishing gradient issues, making training slower and less effective compared to functions like ReLU.